Grouping
Overview
An important scenario when working with data is grouping. Grouping allows you to aggregate data based on a specific column or columns. This enables fetching summary of data based on various aggregate functions.
For example, you may want to group orders by the customer column and then count the number of orders and their total value in each group. In SQL, this can be done using the GROUP BY clause as follows:
SELECT CustNo, Count([OrdNo]), SUM(DNOrdSum)
FROM [Ord]
GROUP BY CustNoWhen grouping data, you can select:
- The columns that you want to group by. The rows with the same value in the selected columns are grouped together.
- The aggregate functions that you want to apply to the grouped data. The aggregate functions are applied to the columns that are not included in the
GROUP BYclause.
Because the WHERE clause is evaluated before the GROUP BY clause, you can use the WHERE clause to filter the rows that are included in the grouping. For instance, if we want to take into account only the orders in a specific interval (let’s say the current month) we can apply a filter as follows:
SELECT CustNo, Count(OrdNo), SUM(DNOrdSum)
FROM Ord
WHERE ChDt > 20231101
GROUP BY CustNoHowever, filtering the rows in the WHERE clause is not always possible. For instance, if we want to retrieve data only for customers that made purchases over some specific amount, we cannot use the WHERE clause because the aggregated sum is not a table column.
In this case, we can use the HAVING clause to filter the groups. The HAVING clause is evaluated after the GROUP BY clause and it can be used to filter the groups based on aggregate functions.
An example is shown here:
SELECT CustNo, Count(OrdNo), SUM(DNOrdSum)
FROM Ord
WHERE ChDt > 20231101
GROUP BY CustNo
HAVING SUM(DNOrdSum) > 1000You can also specify a sorting order for the resulting data using the SORT BY clause. The SORT BY clause is evaluated after the HAVING clause.
In the following example, data is sorted ascending by the customer number.
SELECT CustNo, Count(OrdNo), SUM(DNOrdSum)
FROM Ord
WHERE ChDt > 20231101
GROUP BY CustNo
HAVING SUM(DNOrdSum) > 1000
SORT BY CustNo ASCThe capabilities to group data and filter based on aggregate functions in available in BNXT GraphQL as well. The following sections describe how to use the groupBy and having clauses in BNXT GraphQL.
The connection type
In the previous section, we learned about the connection types and how to perform queries using them. Every connection types has a set of parameters that allows to filter, sort, paginate, but also group. An example is shown in the following image for the order table:
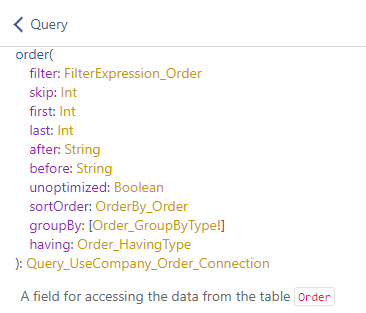
The following parameters can be used to group data:
| Parameter | Description |
|---|---|
filter | Specifies the filter expression. The filter expression is evaluated before the groupBy clause. |
groupBy | Specifies the columns that you want to group by. The rows with the same value in the selected columns are grouped together. |
having | Specifies the aggregate functions that you want to apply to the grouped data. The aggregate functions are applied to the columns that are not included in the groupBy clause. The having clause is applied to the data after grouping. |
orderBy | Specifies the sort order of the grouped data. |
Grouping data
The following example shows how to group data using the groupBy parameter. The example groups the orders by the customer number and then counts the number of orders and their total value in each group.
query read_grouped_orders($cid : Int)
{
useCompany(no : $cid)
{
order(
groupBy : [{customerNo : DEFAULT}])
{
items
{
customerNo
aggregates
{
count
{
orderNo
}
sum
{
orderSumNetDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"order": {
"items": [
{
"customerNo": 0,
"aggregates": {
"count": {
"orderNo": 111
},
"sum": {
"orderSumNetDomestic": 3195
}
}
},
{
"customerNo": 10125,
"aggregates": {
"count": {
"orderNo": 1
},
"sum": {
"orderSumNetDomestic": 0
}
}
},
...
]
}
}
}
}To filter the date, you can use the filter parameter. The following example groups the purchase orders by the customer number and then counts the number of orders and their total value in each group. The orders are filtered by amount, which must be positive, and by the order date.
query read_grouped_orders($cid : Int)
{
useCompany(no : $cid)
{
order(
filter : {_and : [
{orderSumNetDomestic : {_gt : 0}},
{orderDate : {_gt : 20210101}},
{customerNo : {_not_eq : 0}}
]},
groupBy : [{customerNo : DEFAULT}])
{
items
{
customerNo
aggregates
{
count
{
orderNo
}
sum
{
orderSumNetDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"order": {
"items": [
{
"customerNo": 10000,
"aggregates": {
"count": {
"orderNo": 289
},
"sum": {
"orderSumNetDomestic": 305400
}
}
},
{
"customerNo": 10001,
"aggregates": {
"count": {
"orderNo": 3
},
"sum": {
"orderSumNetDomestic": 58047
}
}
},
...
]
}
}
}
}You can also filter the aggregated data by using the having parameter. The following example groups the purchase orders by the customer number and then counts the number of orders and their total value in each group. The orders are filtered by amount, which must be positive, and by the order date. The aggregated data is filtered by the total value of the orders, which must be greater than 100000.
query read_grouped_orders($cid : Int)
{
useCompany(no : $cid)
{
order(
filter : {_and : [
{orderSumNetDomestic : {_gt : 0}},
{orderDate : {_gt : 20210101}},
{customerNo : {_not_eq : 0}}
]},
groupBy : [{customerNo : DEFAULT}],
having : {
_sum : {
orderSumNetDomestic : {_gt : 100000}
}
})
{
items
{
customerNo
aggregates
{
count
{
orderNo
}
sum
{
orderSumNetDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"order": {
"items": [
{
"customerNo": 10000,
"aggregates": {
"count": {
"orderNo": 289
},
"sum": {
"orderSumNetDomestic": 305400
}
}
},
{
"customerNo": 10285,
"aggregates": {
"count": {
"orderNo": 186
},
"sum": {
"orderSumNetDomestic": 312975
}
}
}
]
}
}
}
}Finally, you can also sort the data using the orderBy parameter. The following example, expands the previous one by retrieving the data sorted by descending customer number.
query read_grouped_orders($cid : Int)
{
useCompany(no : $cid)
{
order(
filter : {_and : [
{orderSumNetDomestic : {_gt : 0}},
{orderDate : {_gt : 20210101}},
{customerNo : {_not_eq : 0}}
]},
groupBy : [{customerNo : DEFAULT}],
having : {
_sum : {
orderSumNetDomestic : {_gt : 100000}
}
},
orderBy : [{customerNo : DESC}])
{
items
{
customerNo
aggregates
{
count
{
orderNo
}
sum
{
orderSumNetDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"order": {
"items": [
{
"customerNo": 10285,
"aggregates": {
"count": {
"orderNo": 186
},
"sum": {
"orderSumNetDomestic": 312975
}
}
},
{
"customerNo": 10000,
"aggregates": {
"count": {
"orderNo": 289
},
"sum": {
"orderSumNetDomestic": 305400
}
}
}
]
}
}
}
}The groupBy argument
The type of the group by argument is an array of non-null objects of the type <tablename>_GroupByType. An example is Order_GroupByType for the Order table. Each element of the array specifies one column for grouping. Their order in the GROUP BY clause is the one in which they appear in the array. Let’s take the following example:
groupBy : [{customerNo : DEFAULT}, {orderDate : DEFAULT}]This groups the data by the customerNo and the orderDate columns.
When you specify a column for grouping, you must also specify the kind of grouping that you want to perform. The possible values are:
| Value | Description |
|---|---|
DEFAULT | The default grouping. The rows with the same value in the column are grouped together. |
ROLLUP | The ROLLUP grouping. This creates a group for each combination of column expressions and also rolls up the results into subtotals and grand totals. |
While the column order is not important for the DEFAULT grouping, it is important for the ROLLUP grouping. For instance, GROUP BY ROLLUP (A, B, C) creates groups for each combination of column expressions as show in the following list:
A, B, C
A, B, NULL
A, NULL, NULL
NULL, NULL, NULLTo learn more about the ROLLUP grouping, see the SELECT - GROUP BY- Transact-SQL documentation.
To show how this work, lets take the following example: select transactions grouped by account number and period.
First, we use DEFAULT for account number and ROLLUP for period:
query read_gla_transactions_grouped($cid : Int)
{
useCompany(no : $cid)
{
generalLedgerTransaction(
filter : {
_and: [
{accountNo : {_gte : 3000}},
{year : {_gte : 2020}}
]},
groupBy: [
{accountNo : DEFAULT},
{period : ROLLUP},
],
having : {
_sum : {postedAmountDomestic : {_not_eq : 0}}
})
{
items
{
accountNo
period
aggregates
{
sum
{
postedAmountDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"generalLedgerTransaction": {
"items": [
{
"accountNo": 3000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": -4950
}
}
},
{
"accountNo": 3000,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": -4950
}
}
},
{
"accountNo": 4000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 450
}
}
},
{
"accountNo": 4000,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": 450
}
}
},
{
"accountNo": 4410,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 13035
}
}
},
{
"accountNo": 4410,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": 13035
}
}
}
]
}
}
}
}Due to the applied filter, the result includes the account numbers 3000, 4000, and 4410 and the period 12.
The result is a series of groups for the following combinations:
| Account number | Period |
|---|---|
| 3000 | 12 |
| 3000 | 0 |
| 4000 | 12 |
| 4000 | 0 |
| 4410 | 12 |
| 4410 | 0 |
Next, we change the grouping type use ROLLUP for account number and DEFAULT for period:
query read_gla_transactions_grouped($cid : Int)
{
useCompany(no : $cid)
{
generalLedgerTransaction(
filter : {
_and: [
{accountNo : {_gte : 3000}},
{year : {_gte : 2020}}
]},
groupBy: [
{accountNo : ROLLUP},
{period : DEFAULT},
],
having : {
_sum : {postedAmountDomestic : {_not_eq : 0}}
})
{
items
{
accountNo
period
aggregates
{
sum
{
postedAmountDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"generalLedgerTransaction": {
"items": [
{
"accountNo": 3000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": -4950
}
}
},
{
"accountNo": 4000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 450
}
}
},
{
"accountNo": 4410,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 13035
}
}
},
{
"accountNo": 0,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 8535
}
}
}
]
}
}
}
}The result is a series of groups for the following combinations:
| Account number | Period |
|---|---|
| 3000 | 12 |
| 4000 | 12 |
| 4410 | 12 |
| 0 | 12 |
Finally, let’s use ROLLUP for both account number and period:
query read_gla_transactions_grouped($cid : Int)
{
useCompany(no : $cid)
{
generalLedgerTransaction(
filter : {
_and: [
{accountNo : {_gte : 3000}},
{year : {_gte : 2020}}
]},
groupBy: [
{accountNo : ROLLUP},
{period : ROLLUP},
],
having : {
_sum : {postedAmountDomestic : {_not_eq : 0}}
})
{
items
{
accountNo
period
aggregates
{
sum
{
postedAmountDomestic
}
}
}
}
}
}{
"data": {
"useCompany": {
"generalLedgerTransaction": {
"items": [
{
"accountNo": 3000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": -4950
}
}
},
{
"accountNo": 3000,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": -4950
}
}
},
{
"accountNo": 4000,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 450
}
}
},
{
"accountNo": 4000,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": 450
}
}
},
{
"accountNo": 4410,
"period": 12,
"aggregates": {
"sum": {
"postedAmountDomestic": 13035
}
}
},
{
"accountNo": 4410,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": 13035
}
}
},
{
"accountNo": 0,
"period": 0,
"aggregates": {
"sum": {
"postedAmountDomestic": 8535
}
}
}
]
}
}
}
}This time, we get the following combinations:
| Account number | Period |
|---|---|
| 3000 | 12 |
| 3000 | 0 |
| 4000 | 12 |
| 4000 | 0 |
| 4410 | 12 |
| 4410 | 0 |
| 0 | 0 |
The having argument
The type of the having argument is an object of the type <tablename>_HavingType. An example is Order_HavingType for the Order table. The having clause is applied to the data after grouping and defines filters on aggregated data. The <tablename>_HavingType type has the following fields:
- all the columns in the table
- all the available aggregate functions, such as
SUMandCOUNT, but prefixed with an underscore:_sum,_count, etc. _andand_oroperators that allow to combine multiple conditions
The available aggregate functions are listed in the following table:
| Aggregate | Column types | Description |
|---|---|---|
sum | numerical | The sum of all the values. |
sumDistinct | numerical | The sum of all distinct values. |
average | numerical | The average of all the values. |
averageDistinct | numerical | The averate of all distinct values. |
count | numerical | The number of the items. |
countDistinct | numerical | The number of distinct items. |
minimum | numerical, date, time | The minimum value. |
maximum | numerical, date, time | The maximum value. |
variance | numerical | The statistical variance of all the values. |
varianceDistinct | numerical | The statistical variance of all the distinct values. |
variancePopulation | numerical | The statistical variance for the population of all the values. |
variancePopulationDistinct | numerical | The statistical variance for the population of all the distinct values. |
standardDeviation | numerical | The statistical standard deviation of all the values. |
standardDeviationDistinct | numerical | The statistical standard deviation of all the distinct values. |
standardDeviationPopulation | numerical | The statistical standard deviation for the population of all the values. |
standardDeviationPopulationDistinct | numerical | The statistical standard deviation for the population of all the distinct values. |
In the previous example we have used this condition:
having : {_sum : {orderSumNetDomestic : {_gt : 100000}}}This is equivalent to the following SQL clause:
HAVIG SUM(DNOrdSum) > 100000Because of the nature of GraphQL, the order of fields is:
- aggregate function (AF)
- column name (COL)
- operator (OP)
- value
Therefore, the specification {AF : {COL : {OP : value}}} is translated to AF(COL) OP value and not AF(COL OP value).
You can build complex filters such as the following where we select all the groups either have the count of orders greater than 100 or the sum of the order values is between 100000 and 200000:
having : {
_or: [
{_count :{orderNo : {_gt : 100}}},
{
_and : [
{_sum : {orderSumNetDomestic : {_gt : 100000}}},
{_sum : {orderSumNetDomestic : {_lt : 200000}}},
]
}
]
}The operators used in having clauses are the same used for filter expressions (for the filter argument). To learn more about these, see Filtering.
Limitations
There are also some limitations when grouping data that you must be aware of:
- You cannot use pagination. The
first/afterandbefore/lastarguments do not work. - You cannot group by or filter data from a joined table.
- Sorting does not include the aggregated data.